Stance Classification
By Shashank Rajiv Moghe
In my second year of Bachelors in Mechatronics, I got very interested in AI. The progress in AI has been extremely quick, and the extension of the field to robotics is inevitable. I with a group of friends participated in a competition outside the college’s purview, called the IEEE BigMM Data Challenge (2020).
As a team we were all first and second years, who with considerable effort had managed to teach ourselves the basics of python and machine learning. The problem statement given was to do a stance classification based on tweets in multiple categories, with no other outside information. We came second in the overall challenge, and IEEE graciously provided us the opportunity to share our research work in the journal (link).
We tried a whole host of classifiers and pre-processing methods (and yes, we checked what would happen with different random seeds too >~<), the thing that we found had the biggest impact with this text based, heavily biased dataset was the pre-processing steps. The problem then became to find out which of the available preprocessing steps had the largest impact, and how we could leverage it with a simpler classifier.
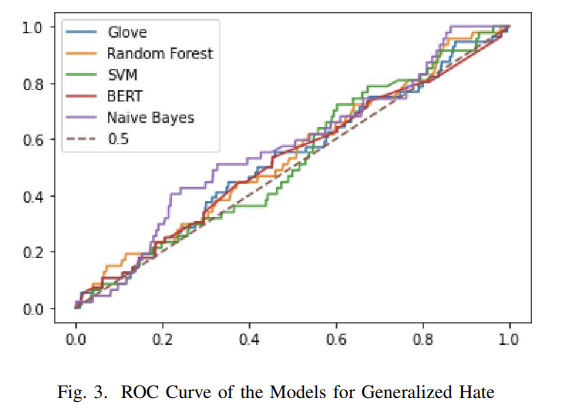
We ended up going for a mixed model, testing multiple test-train splits, stemming and lemmatization and built a system that provided an overall accuracy of over 90% which was great for such a dataset. Just to give an idea of how skewed the dataset was, here is the ROC results for the category of “Generalized Hate”.